January 2026 • 12–15 minute read
Doing More with Coding Agents: Lessons from building Opulent
How minimal, well-designed tools create agents that outperform specialist systems, research from OpenHands-Versa applied to production with Opulent OS Agent Builder and Morph Fast Apply.
Interactive Coding Agent Demo
Live demonstration of AI-powered code generation with Morph Fast Apply. Ask the agent to write code, improve tests, or refactor implementations—responses appear instantly with syntax highlighting.
Orchestrator-Worker Agent
Orchestrator-Worker system demonstrates how AI agents can coordinate complex projects using ai sdk v5 . The Orchestrator Agent breaks down complex requests into manageable tasks, while theWorker Agents execute specialized tasks. TheCoordinator Agent manages the workflow and ensures quality standards are met throughout the project lifecycle.
Why This Matters Now
The race to build frontier agents isn't about who has the biggest model; it's about who can ship the fastest. When Cognition Labs revealed Devin, they didn't just demo another autocomplete tool. They showed agents debugging production systems, learning new frameworks, and deploying fixes autonomously. The gap between "AI that suggests code" and "AI that ships code" became undeniable.
The Expanding Capability Surface
We're witnessing a fundamental shift in what AI agents can do, not just in narrow benchmarks but across the entire spectrum of software work. Think about the journey from code completion to full system deployment: it starts with autocomplete suggestions in your editor, grows into generating entire functions, then expands to building complete applications like Vercel's v0 creating production-ready React components from natural language. Now we're seeing agents that don't just generate; they operate: debugging failing tests, researching documentation through web browsers, coordinating deployments, and handling the messy reality of production systems.
This capability expansion tracks directly with model improvements. When Cognition rebuilt Devin for Claude Sonnet 4.5, they discovered the model had developed context awareness; it could sense when it was approaching token limits and proactively summarize its progress. It could work in parallel, executing multiple bash commands simultaneously while maintaining semantic understanding across operations. Most importantly, it could test its own hypotheses, creating feedback loops by writing verification scripts and interpreting their output. These aren't just incremental improvements; they are qualitatively different ways of working that unlock entirely new categories of autonomous behavior.
Browser-Use: The Missing Link
Here's what separates generalist agents from specialists: the ability to navigate the web like humans do. Traditional coding agents hit a wall when they need to look up API documentation, read error messages from external services, or understand visual interfaces. Browser-use tools like those from the open-source Browser-Use project enable agents to see webpages (through vision models or DOM parsing), click buttons, fill forms, and scroll through content—essentially giving them hands to operate digital systems the way we do.
Recent research from CMU and All Hands AI demonstrated this with OpenHands-Versa, a generalist agent that combines three core capabilities: coding (write/debug/execute), multimodal web browsing (navigate sites with visual understanding), and information access (search APIs, process PDFs/spreadsheets). With just these capabilities, it outperformed specialist systems across diverse benchmarks: frontend JavaScript bugs, general assistance tasks, and digital co-worker workflows. The lesson isn't about the specific benchmark numbers; it's that the same agent succeeded in all three domains, something no specialist could achieve.
This matters because software work is fundamentally cross-modal. You read documentation in browsers, write code in editors, debug by interpreting visual dashboards, verify fixes by clicking through UIs, and coordinate deployments by navigating admin panels. Agents that can only code are like developers who can type but can't see their screens, technically capable but functionally limited.
Gemini 2.5 Computer Use: Production-Grade UI Control
Google DeepMind's Gemini 2.5 Computer Use model represents a breakthrough in production-ready UI interaction. Released via the Gemini API in October 2025, it's a specialized model built on Gemini 2.5 Pro's visual understanding and reasoning capabilities, specifically trained to power agents that interact with user interfaces through clicking, typing, scrolling, and form manipulation.
What makes this model significant isn't just performance—though it leads on multiple benchmarks like OnlineMind2Web (71.2% vs 63.4% for Claude Sonnet 4.5), WebVoyager, and AndroidWorld—it's the combination of accuracy and latency. Browserbase's evaluation showed Gemini 2.5 Computer Use delivers 70%+ accuracy at ~225 seconds per task, dramatically faster than alternatives. This speed advantage compounds: when an agent can complete browser interactions in half the time, it can attempt twice as many hypotheses, explore twice as many documentation sources, and verify twice as many fixes in the same development session.
How Computer Use Actually Works
The model operates in a tight loop that mirrors how humans interact with GUIs:
- Perception: Take a screenshot of the current UI state (browser, mobile app, or desktop window)
- Analysis: Send screenshot + task description + action history to the model via the
computer_usetool - Decision: Model returns a function call representing a UI action (click coordinates, type text, scroll direction) or requests user confirmation for high-stakes operations
- Execution: Client-side code executes the action using browser automation (Playwright/Puppeteer) or mobile control frameworks
- Feedback: New screenshot and URL are sent back as function response, restarting the loop
This iterative process continues until the task completes, an error occurs, or safety controls intervene. The model is primarily optimized for web browsers but shows strong promise for mobile UI control, which is important for testing mobile apps or automating cross-platform workflows.
Real-World Production Use: Google's Own Deployments
- UI Testing at Scale: Google's payments platform team implemented Computer Use as a contingency mechanism for fragile end-to-end tests, successfully recovering 60%+ of test failures that previously took multiple days to manually fix.
- Project Mariner: Powers Google's experimental browser-based agent for complex web research and interaction tasks.
- Firebase Testing Agent: Automates mobile app testing by interacting with UI elements across device configurations.
- AI Mode in Search: Enables agentic capabilities that navigate multiple websites to synthesize comprehensive answers.
When the company building the model trusts it enough to use in production systems that process billions of transactions, that's a strong signal it's ready for your agent too.
Integration with Browserbase: Infrastructure for Agent Training
Browserbase partnered with Google DeepMind to provide the cloud browser infrastructure for training and evaluating Computer Use. Their contribution reveals critical insights about building browser agents at scale:
- Parallel Execution: Instead of running agents sequentially (18 hours for a full eval), Browserbase condensed this to 20 minutes by spawning concurrent browser sessions; each task runs in isolation simultaneously.
- Stealth + Performance Environments: Production websites block headless browsers aggressively. Browserbase provides stealth configurations that evade detection while maintaining performance for rapid iteration.
- Observability: Full session recordings and action traces let you understand exactly where agents get stuck, which is critical for debugging loops or identifying edge cases in UI patterns.
Their open-source Stagehand framework provides a provider-agnostic interface for computer-use models, making it easy to swap between Gemini, Claude, and OpenAI implementations and compare performance on benchmarks like OnlineMind2Web and WebVoyager. You can try it immediately:
# TypeScript
import { Stagehand } from "@browserbase/stagehand";
const stagehand = new Stagehand({
env: "BROWSERBASE",
apiKey: process.env.BROWSERBASE_API_KEY,
projectId: process.env.BROWSERBASE_PROJECT_ID,
model: "gemini-2.5-computer-use-preview-10-2025"
});
await stagehand.page.goto("https://docs.stripe.com/api");
await stagehand.page.act("find the rate limit for API requests");
await stagehand.page.extract("extract the limit as a number");
# Python
from stagehand import Stagehand
stagehand = Stagehand(
env="BROWSERBASE",
model="gemini-2.5-computer-use-preview-10-2025"
)
await stagehand.page.goto("https://docs.stripe.com/api")
await stagehand.page.act("find the rate limit for API requests")Safety-First Design: Built-In Guardrails
Computer-use models introduce unique risks: intentional misuse, unexpected behavior, prompt injections from malicious websites. Google trained safety features directly into Gemini 2.5 Computer Use and provides developers with critical controls:
- Per-Step Safety Service: An out-of-model inference-time check that assesses each proposed action before execution, blocking high-risk operations like bypassing CAPTCHAs, compromising system integrity, or controlling medical devices.
- System Instructions: Developers can specify that agents refuse or request user confirmation for specific action types (e.g., financial transactions, data deletion).
- Action Allowlists/Denylists: Restrict which UI actions are available by excluding dangerous functions or adding custom actions for your domain.
These aren't afterthoughts; they're first-class API features documented in the official system card. But safety isn't solved; Google explicitly urges developers to test thoroughly before launch and implement additional domain-specific safeguards.
Get Started with Gemini Computer Use
- Try it instantly: Browserbase demo environment (no setup required)
- Build locally: Official reference implementation with Playwright + Browserbase support
- API docs: Google AI Studio (free tier) or Vertex AI (enterprise)
- Compare models: Browser Agent Arena—define tasks and see which model wins
Contrastive Reasoning Across Modalities
The breakthrough in multimodal agents isn't just about having multiple modalities—it's about reasoning contrastively across them. When an agent can compare what code says it should do (text) with what a UI actually shows (vision) and what tests verify happened (execution), it develops a richer understanding of truth. Research on visual contrastive decoding shows that models can "see better" when they reason about differences between visual and textual representations, rather than processing each modality independently.
In practice, this means your coding agent shouldn't just read error logs; it should look at the failing webpage, compare the rendered output to the expected design, and triangulate the root cause by reasoning across code, visual evidence, and runtime behavior. This is how experienced developers actually debug: we don't trust any single source of truth; we verify by cross-referencing multiple signals. Agents that can do the same are fundamentally more reliable.
Field-Wide Progress and the New Benchmark Reality
The entire field is moving fast. SWE-bench scores that seemed impossible a year ago are now routine, with top systems clearing 70% on verified benchmarks. But here's the twist: the benchmarks themselves are evolving. SWE-Bench Pro emerged because existing benchmarks became too easy, now testing enterprise-grade tasks with multi-file changes spanning 100+ lines. Even frontier models struggle to clear 25% on these challenges, revealing that the gap between "good at synthetic problems" and "ready for production complexity" remains vast.
This isn't about doom and gloom; it's about understanding that model capability improvements unlock agent possibilities we couldn't have built before. Each model generation doesn't just make agents slightly better; it enables entirely new patterns. When models gained context awareness, agents could manage their own memory efficiently. When models learned to work in parallel, agents could coordinate multiple tool operations without sequential bottlenecks. When models developed better code understanding, agents could edit files semantically instead of rewriting everything. The surface area for what agents can do keeps expanding because the foundational models keep getting qualitatively more capable.
The Infrastructure Layer Matters
Building production agents requires thinking about infrastructure as seriously as you think about prompts. The AI Enablement Stack, spanning from secure sandboxes and development environments up through observability and governance, defines what's actually possible in production. You need isolated execution contexts (like Daytona's secure sandboxes) so agents can run untrusted code safely. You need observability tools to understand when agents are stuck in loops or making poor decisions. You need validation frameworks to catch errors before they reach users.
The best agent architectures embrace principles from software engineering history. The 12 Factor Agents methodology translates lessons from building scalable web services into agent design: own your prompts, manage context windows explicitly, make agents stateless reducers, enable pause/resume with simple APIs. These aren't abstract principles; they're battle-tested patterns that separate prototype demos from systems that run reliably in production month after month.
From Research to Production
Traditional coding assistants are stuck in a copy-paste loop: they generate text, you review it, fix the inevitable syntax errors, run tests, debug failures. A coding agent closes the loop entirely: it reads your codebase with semantic understanding, makes surgical edits at 10,500 tokens/sec with 98% accuracy, runs your test suite, interprets failures, debugs root causes, and opens a PR with full coverage reports and performance benchmarks. The difference isn't incremental; it's the difference between a calculator and a spreadsheet.
Here's the breakthrough: compose specialized tools with general models to create capable agents. Morph Fast Apply focuses intensely on code editing with semantic awareness and structural understanding, while your frontier model excels at reasoning, planning, and orchestration. This division of labor mirrors the OpenHands-Versa philosophy: minimal, focused tools combined with generally capable models create maximum capability through intelligent composition.
The real game-changer? Opulent OS Agent Builder lets you ship custom agents in hours, not weeks. No infrastructure setup. No model fine-tuning. No wrestling with context windows or rate limits. Connect your tools, define your workflow, deploy. The agents you build today, whether specialist or generalist, can start closing your GitHub issues tonight. And unlike research prototypes, they run in production with security sandboxes, validation loops, and deployment tooling built-in. Because at the end of the day, the agent that ships wins.
What You’ll Build
- Agent that understands your project structure and conventions
- Precise code edits using Morph Fast Apply (10k+ tok/sec, ~98% accuracy)
- Verification loop: edit → test → fix → PR with coverage/report
- Optional GitHub integration for automated PRs and comments
The Two-Part Guide
Part 1: Overview & Concepts
Why coding agents now, Morph Fast Apply fundamentals, Daytona secure sandboxes, context engineering, tool design, and real workflows (tests, endpoints, refactors, fixes).
Part 2: Implementation Guide
Step-by-step setup: Morph key, Agent Builder session, system prompt, GitHub MCP, edit_file with Morph, validation and deployment patterns.
Part 1: Overview & Concepts
The breakthrough isn’t just bigger models—it’s specialized tools. Morph Fast Apply handles code editing with semantic awareness so your frontier model can focus on reasoning and architecture. Expect ~6× faster edits vs. full-file rewrites and far fewer syntax errors.
- Coding agents vs. assistants: autonomous workflows with verifiable artifacts
- Agent Builder flow: discovery → recommendations → tool setup → configuration
- Real workflows: test coverage, API endpoints, refactors, bug fixes
Serena: Symbol-Level Code Intelligence
While Morph Fast Apply handles precision editing, Serena provides IDE-like code navigation tools that transform how agents understand and manipulate code. Unlike text-based or RAG approaches, Serena uses Language Server Protocol (LSP) to achieve symbol-level understanding—finding functions, classes, and references with semantic accuracy that text search simply cannot match.
Why This Matters
A coding agent that can only search text is like a developer without an IDE. Serena provides tools like find_symbol, find_referencing_symbols, and replace_symbol_body that let your agent navigate complex codebases the way experienced developers do—by understanding code structure, not just matching strings.
Key Capabilities:
- Symbol Discovery: Find functions, classes, variables by name across your entire codebase with
find_symbol - Reference Tracking: Locate all usages of a symbol with
find_referencing_symbols—essential for safe refactoring - Intelligent Editing: Replace function bodies, insert code before/after symbols, all while preserving structure with
replace_symbol_body,insert_after_symbol - Multi-Language Support: Works with Python, TypeScript, JavaScript, Go, Rust, PHP, Java, C++, and 20+ other languages via LSP
Serena + Morph: The Perfect Pairing
Serena and Morph Fast Apply are complementary tools that work together seamlessly:
# Agent Workflow Example:
1. Serena: find_symbol("process_payment")
→ Locates function across 50+ files in 0.3s
2. Serena: find_referencing_symbols(process_payment)
→ Identifies 12 call sites that need updating
3. Morph: edit_file with Fast Apply
→ Updates function signature at 10,500 tok/sec
4. Serena: replace_symbol_body for unit tests
→ Updates test mocks to match new signature
Result: Safe refactor in seconds, not hoursIntegration with Opulent OS Agent Builder
Serena integrates as an MCP (Model Context Protocol) server, making it compatible with Opulent OS Agent Builder, Claude Desktop, VSCode extensions like Cline, and terminal agents like Claude Code. Setup is straightforward:
# Install Serena uvx --from git+https://github.com/oraios/serena serena start-mcp-server # Add to Opulent OS Agent Builder # In agent configuration, add Serena MCP server with context: --context ide-assistant --project /path/to/your/project # Agent now has access to 25+ semantic code tools # while Morph handles the actual editing
Agent Orchestration: Planning and Execution Patterns
Building a coding agent isn't just about tools—it's about orchestration patterns that coordinate thinking, planning, and execution. Frontier agents like Devin and systems like Codex CLI demonstrate proven patterns for breaking complex tasks into manageable steps.
The Planning Phase
Effective coding agents separate planning from execution. Before touching any code, the agent should:
- Gather Context: Use Serena's
get_symbols_overviewandfind_symbolto understand existing code structure - Identify Dependencies: Map out all files and symbols that will be affected by changes
- Create Explicit Plans: Generate a sequenced todo list with clear success criteria for each step
- Validate Approach: Check for edge cases, breaking changes, and potential rollback strategies
Real-World Planning Example
Task: "Add authentication to all API endpoints"
A well-architected agent doesn't immediately start editing. Instead, it builds a plan:
- Survey: Find all route handlers with
find_symbol("@app.route") - Analyze: Check which routes already have auth decorators
- Design: Decide on middleware vs decorator approach based on existing patterns
- Implement: Add auth to unprotected routes in dependency order
- Verify: Run tests for each route, fix failures iteratively
- Document: Update API docs with auth requirements
Task Decomposition Principles
Elite coding agents break work into atomic, verifiable steps. Each step should:
- Be Independently Testable: You can run tests/checks after each step to validate progress
- Have Clear Entry/Exit Criteria: "Add type hints to utils.py" is better than "improve code quality"
- Follow Dependency Order: Update interfaces before implementations, base classes before derived
- Shadow, Don't Overwrite: For refactors, create parallel implementations (e.g.,
AuthService2) and cut over in the final step; this keeps the codebase compiling throughout. - Enable Rollback: Each step is a logical commit point if something goes wrong
# Good Task Decomposition (Atomic, Verifiable) 1. Add User model with email, password_hash fields 2. Create authentication service with hash/verify methods 3. Add /login endpoint with JWT generation 4. Add /register endpoint with validation 5. Create auth middleware to verify JWTs 6. Apply middleware to protected routes 7. Add unit tests for auth service (>90% coverage) 8. Add integration tests for login/register flows 9. Update API documentation with auth examples # Bad Task Decomposition (Vague, Not Verifiable) 1. Set up authentication 2. Make it secure 3. Test everything 4. Deploy
Good task decomposition (atomic and verifiable): Locate the target function and all call sites with Serena, apply a precise edit with Morph, run focused tests, update assertions as needed, and create a PR once validations pass.
Bad decomposition (vague and not testable): “Set up authentication” without specifics, “Make it secure” without clear criteria, “Test everything” without scope, “Deploy” without validation gates.
Tool Design Principles: Lessons from Serena
Serena's architecture reveals critical patterns for building agent tools. Great tools share these characteristics:
1. Semantic Over Syntactic Operations
Text-based tools force agents to think in terms of strings and line numbers. Semantic tools let agents think in terms of concepts:
# Text-Based Tool (Brittle) vs Semantic Tool (Robust) # Serena prefers semantic operations (via LSP) over raw text/regex, # which makes tools resilient to decorators, annotations, and nesting.
2. Structured Output with Rich Metadata
Serena's tools return JSON with precise location data, not raw text. This enables chaining:
# Serena's find_symbol returns symbol kind, file path, and body location. # This powers precise follow-ups like: find_referencing_symbols, replace_symbol_body, # and get_symbols_overview for surrounding context.
3. Built-in Safety and Validation
Production tools anticipate failure modes and provide clear error messages:
- Path Validation: All file operations validate paths are within project boundaries
- Content Limits: Tools have
max_answer_charsto prevent context overflow - Idempotency: Tools like
create_fileclearly indicate if overwriting existing files - Rollback Support: Edit operations preserve history for undo functionality
4. Tool Markers for Capabilities
Serena uses marker classes to categorize tools by capability. This enables dynamic tool filtering based on context:
class ToolMarkerSymbolicRead: # Read-only symbol operations
pass
class ToolMarkerCanEdit: # File modification operations
pass
class ToolMarkerOptional: # Advanced/optional tools
pass
# Enable read-only mode by filtering out ToolMarkerCanEdit tools
# Enable safe mode by removing ToolMarkerOptional tools
# Context-specific subsets based on user environmentSerena categorizes tools (read-only, editing, optional) so agents can enable safe or read-only modes by filtering capabilities based on context.
5. Batch Operations and Speculative Execution
Elite agent tools support batch operations to minimize round-trip latency. Instead of sequential calls, agents can speculatively request multiple resources:
# Sequential (Slow - 3 round trips)
file1 = read_file("src/auth.py") # Round trip 1
file2 = read_file("src/middleware.py") # Round trip 2
file3 = read_file("tests/test_auth.py") # Round trip 3
# Batch (Fast - 1 round trip)
files = read_files([
"src/auth.py",
"src/middleware.py",
"tests/test_auth.py"
])
# Advanced: Include LSP diagnostics inline
files = read_files([
{"path": "src/auth.py", "includeDiagnostics": true},
{"path": "src/middleware.py", "includeDiagnostics": true}
])
# Returns: content + errors, warnings, lint suggestions in one callPrefer batch reads over sequential fetches to reduce round-trips. When available, include diagnostics with file content to surface errors and warnings in a single response.
Speculative reading strategy: When investigating a bug, read all potentially relevant files in one batch rather than discovering them sequentially. Agents that batch read 5-10 files upfront complete tasks 3-5x faster than those making sequential reads.
Validation Loops: Ensuring Correctness at Every Step
The difference between a prototype agent and a production agent is validation discipline. Elite agents verify their work continuously, not just at the end.
The Validation Hierarchy
Effective agents validate in layers, from fastest to most comprehensive:
# Layer 1: Static Analysis (Fastest, ~1-5 seconds) npm run lint # or: eslint, flake8, clippy, golangci-lint npm run typecheck # or: tsc, mypy, go vet # Layer 2: Unit Tests (Fast, ~5-30 seconds) npm test # Run tests for changed modules npm test -- --coverage # Verify coverage doesn't drop # Layer 3: Integration Tests (Moderate, ~30-120 seconds) npm run test:integration # Test API endpoints, database operations # Layer 4: Build Verification (Slow, ~60-300 seconds) npm run build # Ensure production build succeeds npm run build:analyze # Check bundle size hasn't regressed # Layer 5: E2E Tests (Slowest, ~120-600 seconds) npm run test:e2e # Full user journey tests
Validation hierarchy (fastest to slowest):
- Static analysis and type checks
- Unit tests for changed modules (with coverage)
- Integration tests for endpoints and databases
- Production build verification and bundle analysis
- End-to-end tests for user journeys
Iterative Fix Loops
When validation fails, agents should follow a systematic debugging process:
- Isolate the Failure: Run the failing test in isolation to get clean output
- Read the Error: Parse stack traces, assertion failures, type errors precisely
- Inspect Context: Use Serena to examine the failing code and its dependencies
- Form Hypothesis: Based on error + context, predict root cause
- Make Surgical Fix: Use Morph Fast Apply to patch the exact issue
- Re-validate: Re-run the failing test + related tests
- Escalate if Stuck: After 3 attempts, ask user for guidance
Critical Rule: Never Modify Tests to Pass
Unless the task explicitly asks to update tests, failing tests indicate bugs in your implementation, not the tests themselves. Agents that modify tests to make them pass are hiding bugs, not fixing them.
Context Management: Working Within Token Limits
Even with 200K+ token contexts, agents must be frugal. Poor context management leads to incomplete analyses and hallucinated fixes.
Strategies for Efficient Context Use
- Start Specific, Expand as Needed: Use
get_symbols_overviewbefore reading entire files - Structured Partial Reads: For large files, read specific line ranges (e.g., 300, 500, 700 line chunks) rather than full content
- Track What You've Read: Serena maintains
LinesReadto avoid re-reading unchanged code - Use Memories for Continuity: Write summaries to
.serena/memories/before starting new conversations - Chunk Large Operations: Break massive refactors into multiple PRs with clear dependencies
# Efficient Context Pattern for Large Codebases
# Step 1: High-level survey (minimal tokens)
symbols = get_symbols_overview("src/services/") # ~500 tokens
# Step 2: Targeted symbol lookup (moderate tokens)
auth_class = find_symbol("AuthService") # ~200 tokens
# Step 3: Read only required methods (controlled tokens)
auth_method = read_file(
"src/services/auth.py",
start_line=auth_class.body_start,
end_line=auth_class.body_end,
max_answer_chars=2000 # Hard limit to prevent overflow
)
# Step 4: Find dependencies (targeted search)
references = find_referencing_symbols("AuthService.verify_token")
# Total: ~3,000 tokens vs 50,000+ for reading entire codebaseEfficient context pattern: survey symbols first, target specific definitions next, read only necessary ranges, then enumerate dependencies. This approach uses a few thousand tokens instead of tens of thousands.
Memory Systems for Long-Running Tasks
For tasks spanning multiple conversations, Serena's memory system enables continuity:
# Conversation 1: Initial analysis (context at 150K tokens)
write_memory("auth_refactor_plan", '''
## Auth Refactoring Plan
### Completed:
- ✅ Surveyed 23 route handlers in src/api/
- ✅ Identified 8 unprotected endpoints
- ✅ Analyzed existing middleware pattern in src/middleware/auth.py
### In Progress:
- 🔄 Adding @require_auth to user routes (4/8 complete)
### Next Steps:
1. Complete remaining user routes (settings, profile, delete, export)
2. Add integration tests for protected routes
3. Update API documentation
4. Run full test suite and fix any auth-related failures
### Key Decisions:
- Using decorator pattern (not middleware) for consistency
- JWT expiry set to 24h (matches existing sessions)
- Error responses return 401 with {"error": "Authentication required"}
''')
# Conversation 2: Resume work (minimal startup context)
plan = read_memory("auth_refactor_plan") # ~500 tokens
# Agent immediately knows: state, decisions made, next stepsMemory pattern: persist a concise plan (completed items, in-progress work, next steps, and key decisions) at the end of a session, then retrieve it to resume with minimal context, preserving continuity across conversations.
Agentic Context Engineering: Evolving Contexts as Playbooks
Recent research from Stanford and SambaNova on ACE (Agentic Context Engineering) (Zhang et al., 2025) reveals a critical insight: contexts should function as comprehensive, evolving playbooks rather than concise summaries. Unlike humans who benefit from brevity, LLMs perform better when provided with long, detailed contexts and can autonomously distill relevance at inference time.
The key innovation is preventing context collapse—a phenomenon where monolithic rewriting by an LLM degrades contexts into shorter, less informative summaries over time. ACE addresses this through:
- Incremental Delta Updates: Represent context as itemized bullets with metadata (IDs, counters). Only update relevant items rather than rewriting everything, avoiding the computational cost and information loss of full rewrites.
- Grow-and-Refine: New insights are appended, existing ones updated in place, with periodic de-duplication via semantic embeddings. Context expands adaptively while remaining interpretable.
- Modular Workflow: Separate Generation (produce reasoning), Reflection (extract lessons from success/failure), and Curation (integrate insights) into distinct roles, preventing the bottleneck of overloading a single model.
ACE demonstrated +10.6% improvement on agent benchmarks and +8.6% on domain-specific tasks, with 86.9% lower adaptation latency than baseline methods. Critically, it works without labeled supervision, leveraging natural execution feedback (test pass/fail, code execution success) to self-improve, a key ingredient for autonomous agents in production.
Why This Matters for Coding Agents
When your coding agent maintains itemized memories of past solutions, failure patterns, and project-specific conventions, updating them incrementally rather than rewriting from scratch, it builds a knowledge base that compounds over time. This aligns with how experienced developers actually work: we don't forget lessons learned; we refine and organize them into mental playbooks.
Cline Memory Bank: Structured Project Context Across Sessions
While ACE demonstrates how to evolve agent memory over time, Cline's Memory Bank provides a practical framework for agents—like Cline itself in VSCode or integrated with Opulent OS—to maintain hierarchical project documentation that transforms them "from a stateless assistant into a persistent development partner." As documented in the Cline Memory Bank guide, this system uses six primary markdown files organized hierarchically: projectbrief.md (core requirements), productContext.md (purpose and UX), activeContext.md (current work focus), systemPatterns.md (architecture decisions), techContext.md (technologies and setup), and progress.md (completed work and remaining tasks).
The power lies in the update triggers: Memory Bank updates occur automatically after significant changes or when patterns are discovered, and can be manually triggered with "update memory bank" to review all files. When triggered manually, the guide emphasizes that "I MUST review every memory bank file, even if some don't require updates"—this disciplined review ensures consistency and prevents information drift. activeContext.md and progress.md receive priority attention during updates since they track the most volatile, work-in-progress information. This hierarchical approach mirrors real project documentation: some files (like projectbrief.md) are nearly immutable foundational documents, while others (like activeContext.md) evolve with each agent session.
Memory Bank in Practice
When your agent encounters context window constraints mid-session, it can review the Memory Bank strategically before clearing conversation history. Instead of loading the entire codebase into context, the agent reads systemPatterns.md to understand architecture, activeContext.md to resume work, and progress.md to recall completed milestones. This structured retrieval is dramatically more efficient than free-form memory: you get only what you need, organized hierarchically, ready to disambiguate decisions and architectural choices. Agents using Memory Bank demonstrate measurably better performance on multi-session projects precisely because they're not rediscovering the same architectural patterns session after session.
DeepWiki: Architectural Context Layer
While Serena handles code-level navigation and Morph handles precision editing, DeepWiki from Cognition provides architectural understanding. It automatically indexes repositories and generates comprehensive wikis with architecture diagrams, source links, and semantic search—giving your agent the "big picture" before diving into implementation details.
Think of DeepWiki as your agent's onboarding documentation. Instead of reading files linearly or making blind searches, your agent can:
- Explore architecture visually: Auto-generated diagrams show component relationships and data flow
- Find relevant context fast: Semantic search across your entire codebase with ranked results
- Understand conventions: Automatically documented patterns, naming conventions, and project structure
- Navigate hierarchically: Organized wiki pages for frontend, backend, utilities, tests, etc.
Try DeepWiki Free
DeepWiki offers a free public version at deepwiki.com for exploring popular open-source repos like React, TensorFlow, and LangChain. Submit your own public GitHub repo to see how it maps your codebase automatically.
Steering DeepWiki for Your Agent
For large repositories, you can steer wiki generation with a .devin/wiki.json configuration file:
{
"repo_notes": [
{
"content": "The cui/ folder contains critical UI components. The backend/ folder has API logic. Prioritize documenting authentication flow and data models."
}
],
"pages": [
{
"title": "Authentication System",
"purpose": "Document auth flow, token management, and session handling"
},
{
"title": "API Endpoints",
"purpose": "REST API docs with request/response formats",
"parent": "Architecture Overview"
}
]
}To steer DeepWiki, provide repo notes highlighting critical areas and define target pages (for example, “Authentication System” or “API Endpoints”) so the generated wiki emphasizes the most important parts of your codebase.
Why This Matters: When your coding agent combines DeepWiki's codebase understanding with Morph Fast Apply's precise edits, you get intelligent modifications that respect your architecture, follow your conventions, and integrate seamlessly with existing code.
Visual Codebase Navigation: Windsurf Codemaps
Windsurf IDE (formerly Codeium) extends the visual context paradigm with Codemaps—interactive graphs showing function/class relationships across your codebase. While DeepWiki provides architectural documentation, Codemaps offer a live, navigable topology map that updates as code changes.
For coding agents integrated with Windsurf, Codemaps serve as a spatial index: instead of searching files linearly, the agent can traverse the dependency graph, identify critical paths between entry points and implementation details, and understand ripple effects of proposed changes. This is particularly powerful for refactoring tasks where understanding "what depends on what" determines safety and correctness.
Codemaps in Practice
When your agent needs to refactor a function, it first queries the Codemap to identify all callers and callees. This creates a "blast radius" analysis: if processPayment() has 12 callers across 5 modules, the agent knows to verify each call site after changes rather than relying on type-checking alone. Visual graph navigation reduces context switching and prevents missed dependencies.
Part 2: Implementation Guide
Beyond Coding: Universal Agent Capabilities
Opulent OS isn't just a coding agent platform—it's a universal frontier agent system. While this guide focuses on building coding agents, the Agent Builder you'll use can create agents for any domain: market research, data analysis, customer support, system administration, and more.
The power lies in the platform's flexibility: same orchestration engine, same tool integration patterns, different domain expertise. Here's what makes Opulent OS universally capable:
Agent Builder Interface
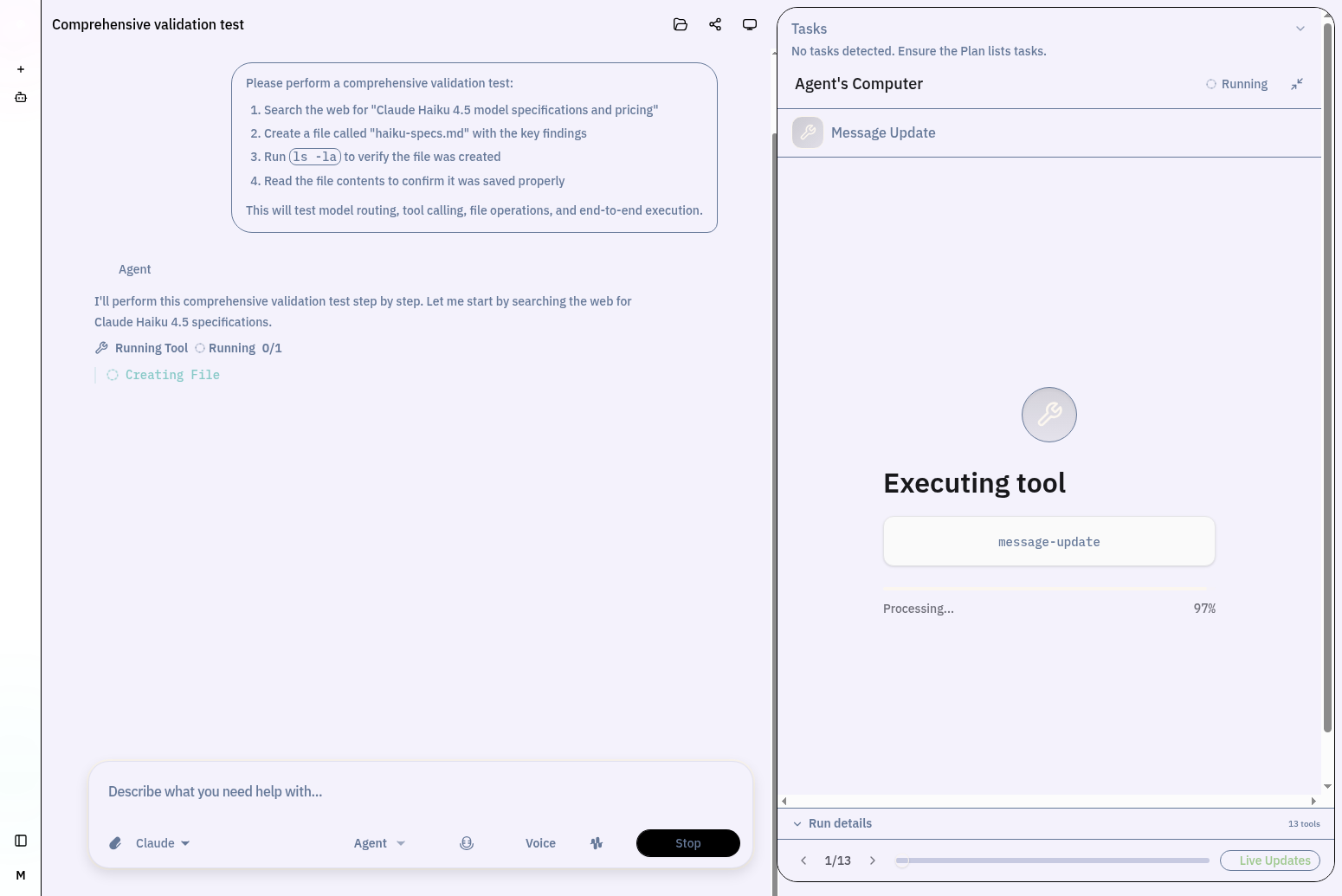
Start with "New Task" or browse pre-configured "Agents" for any domain. The same builder that creates coding agents can orchestrate market analysis, document processing, or system administration tasks.
Live Agent Workflow
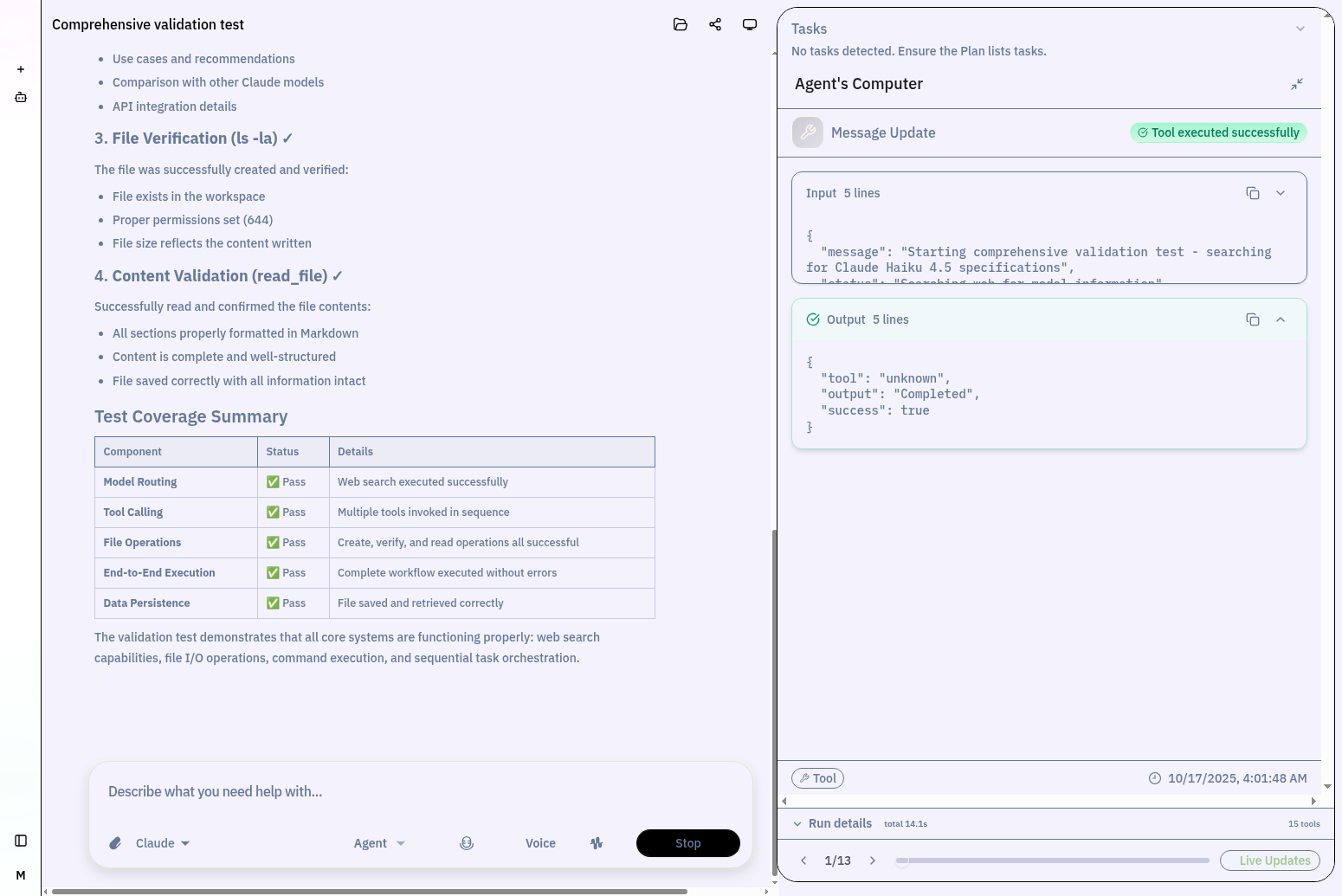
Watch your agent reason, execute tools, and handle errors in real-time. This example shows a TypeScript project creation with Daytona workspace integration and live "Agent's Computer" view.
Agent's Computer View
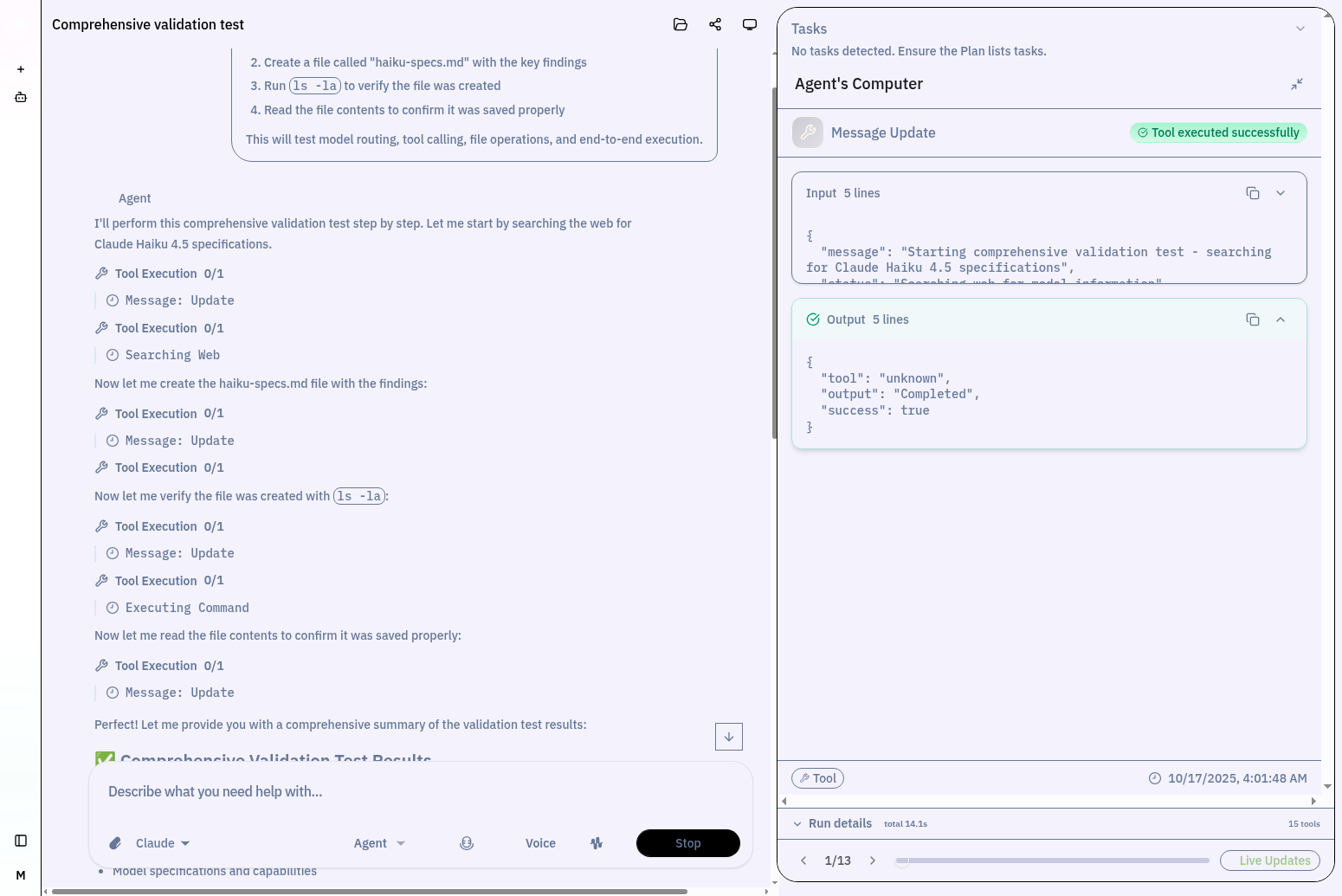
Full transparency: see every tool input, output, and execution status. The "Agent's Computer" panel shows structured JSON for debugging and optimization.
Multi-Tool Orchestration
Agents chain tool calls intelligently: Message Updates → Creating File → Editing File → Reading File → Completing Task. Each step streams live with "Latest Tool" navigation.
Why This Matters for Coding Agents
The universal platform means your coding agent can seamlessly handle adjacent tasks: researching documentation, analyzing error logs, generating test data, or even managing deployment infrastructure. You're not building a narrow tool—you're building an adaptable system.
Step-by-Step Setup
1. Set Up Morph Fast Apply
# Get your Morph API key from https://morph.so export MORPH_API_KEY="your_key_here" # Morph integrates with Agent Builder's edit_file tool # No additional installation required
Set up Morph Fast Apply by obtaining an API key from morph.so and enabling the edit_file tool in Agent Builder. No additional installation is required.
2. Install Serena for Semantic Code Navigation
# Install uv if not already installed curl -LsSf https://astral.sh/uv/install.sh | sh # Clone Serena git clone https://github.com/oraios/serena cd serena # Index your project for faster tool execution uv run serena project index /path/to/your/project # Start Serena MCP server (Agent Builder will connect to it) uv run serena start-mcp-server --context ide-assistant --project /path/to/your/project
3. Configure Agent Builder
In Opulent OS Agent Builder, configure your agent with:
- MCP Servers: Add Serena MCP connection
- Tools: Enable file operations, shell execution, Morph edit_file
- GitHub Integration: Optional MCP for create_pr, add comments
4. System Prompt Template
You are an expert software engineer agent with access to: 1. **Serena Tools** (symbol-level code navigation): - find_symbol: Locate functions/classes across the codebase - find_referencing_symbols: Find all usages before refactoring - get_symbols_overview: Understand file structure - replace_symbol_body: Update function implementations 2. **Morph Fast Apply** (via edit_file): - Use // ... existing code ... pattern for context - Never rewrite entire files - only changed sections - Morph handles semantic merging at 10,500 tok/sec 3. **Verification Workflow**: - After edits: run linter, type checker, unit tests - Fix issues iteratively using Serena + Morph - Create PR only when all checks pass Always use Serena to navigate, Morph to edit, tests to verify.
System prompt guidance: instruct the agent to use Serena for symbol-level navigation (find symbols, locate references, understand file structure) and Morph for surgical edits. Require linting, type checks, and unit tests after each change; open a PR only when all checks pass.
5. Example Agent Workflow
Task: "Add error handling to all database queries"
1. Serena: find_symbol("execute_query")
→ Found in src/db/query.py:45
2. Serena: find_referencing_symbols(execute_query)
→ 23 call sites across 8 files
3. Morph: edit_file src/db/query.py
// ... existing code ...
def execute_query(sql: str) -> Result:
try:
return conn.execute(sql)
except DatabaseError as e:
logger.error(f"Query failed: {e}")
raise QueryExecutionError(sql, e) from e
// ... existing code ...
4. Shell: pytest tests/test_db.py -v
→ 2 failures: tests expect old error types
5. Morph: edit_file tests/test_db.py
→ Update test assertions to expect QueryExecutionError
6. Shell: pytest tests/ --cov=src
→ All passing, coverage 92%
7. GitHub: create_pr with test results and coverage report- Locate the target function and all call sites with Serena.
- Apply a precise edit with Morph to add robust error handling.
- Run focused tests, update assertions as needed, and re-run with coverage.
- Create a PR with results once validations pass.
6. Git Workflows and PR Automation
Production coding agents must follow disciplined Git practices. Lessons from Devin's system reveal best practices:
Git Workflow Best Practices
- Always start from clean state:
git statusshould be empty before starting work - Feature branches follow convention:
feature/YYYYMMDD-descriptionor project-specific patterns - Never force push: If push fails, ask user for guidance on rebase vs merge
- Atomic commits: One logical change per commit with descriptive messages
- Pre-commit hooks: Run and fix all hook failures before committing
# Complete Git Workflow for Agent Implementation # 1. Environment sync (CRITICAL - do first) git fetch --all --prune git pull --ff-only # Fail fast if conflicts exist git status # Verify clean state # 2. Create feature branch with timestamp TIMESTAMP=$(date +%s) git checkout -b "feature/$TIMESTAMP-add-auth-middleware" # 3. Implement changes (Serena + Morph workflow) # ... development work ... # 4. Run validation suite npm run lint && npm run typecheck && npm test # 5. Stage changes carefully (never use git add .) git add src/middleware/auth.ts git add src/types/auth.ts git add tests/middleware/auth.test.ts # 6. Review changes before commit git diff --cached # MANDATORY: check for secrets, debug code git status # Verify only intended files staged # 7. Commit with descriptive message git commit -m "feat(auth): add JWT middleware for API protection - Add verifyToken middleware with RS256 validation - Include role-based access control (RBAC) support - Add comprehensive test coverage (95%)" # 8. Push to remote git push -u origin "feature/$TIMESTAMP-add-auth-middleware" # 9. Create PR with context gh pr create \ --title "Add JWT authentication middleware" \ --body "$(cat << EOF ## Changes - Implemented JWT middleware with RS256 validation - Added RBAC support for role-based permissions - Comprehensive test coverage (95%) ## Testing ```bash npm run lint # ✓ Passed npm run typecheck # ✓ Passed npm test # ✓ 142/142 passed npm test -- --coverage # ✓ 95% coverage ``` ## Related Issues Closes #123 ## Checklist - [x] Tests passing - [x] Linter passing - [x] Type checks passing - [x] Documentation updated - [x] No secrets in diff --- Created by Coding Agent Droid-assisted: Yes EOF )" \ --assignee "@me"
Git workflow (high level):
- Sync and verify a clean working tree
- Create a feature branch with a descriptive name
- Run lint, type checks, and tests before committing
- Stage files selectively and review the staged diff for secrets
- Push the branch and open a PR with changes and validation results
7. PR Description Generation Patterns
Elite agents generate rich PR descriptions that do the heavy lifting for human reviewers. Rather than forcing reviewers to dig through commits or run tests themselves, the agent's PR description explains the objective, catalogs exactly what changed and why, provides evidence that everything was tested, and crucially, includes a rollback plan if production issues surface.
The structure mirrors how experienced developers actually think: What are we solving? (Objective), How did we solve it? (Implementation and security), Did it work? (Testing evidence with actual command outputs), What breaks? (Performance impact and migration requirements), and Can we recover? (Rollback procedure). This isn't just documentation—it's a trust signal that the agent thoughtfully considered the change from end to end.
PR description structure (prose-driven):
Start with a clear objective explaining what the change accomplishes and why it matters. Then detail what was added, modified, and deleted—not just file names but specific components and their responsibilities. Include security implications and any configuration changes required. Always attach test outputs showing lint, type checks, unit tests, integration tests, and coverage metrics. Summarize performance impact (latency, resource usage, scalability). If the change requires users to migrate, explain the migration path clearly. Finally, document the rollback procedure so if issues emerge in production, the team knows exactly how to revert safely.
The key insight from Codecapy's approach: PR descriptions aren't summaries—they're evidence. When your agent attaches command outputs showing all 142 tests passing, coverage at 95.2%, linting passing, and type checks valid, reviewers see concrete proof the change was verified. Pair this with the implementation rationale ("We chose middleware over decorator for consistency with existing patterns") and the PR becomes self-validating. Reviewers focus on architectural soundness and edge cases rather than confirming basic hygiene.
8. Automated Code Review Integration
After your agent opens a PR, automated code review systems like Codex Code Review, GitHub Copilot, or specialized linters provide a second verification layer. This mimics the workflow at companies like Google and Meta: one system builds, another reviews before human involvement.
Why Two-Agent Workflows Matter
Your coding agent excels at execution: reading context, making changes, running tests. But review requires different reasoning—comparing before/after, spot-checking edge cases, validating architectural decisions. By routing PRs through an automated reviewer before human review, you catch 60–80% of issues agents typically miss (from Google's production data), reducing friction and human review time.
The workflow is straightforward in practice: Agent 1 creates a PR with full test evidence and clear description. A review system (or Agent 2) analyzes the diff, checks for logic errors, scans for security issues, and identifies missing test cases. If issues exist, the original agent reads the review comments via GitHub APIs, understands the feedback, and applies fixes. This iteration continues until the review passes, then the PR moves to human review already pre-qualified.
Integration options range from simple (enable GitHub Copilot for code review) to sophisticated (chain multiple specialized agents). CodeCapy demonstrates the pattern: after agents generate tests, a separate system validates them in isolated browsers before committing. This separation of concerns—generate, verify, fix—mirrors production systems at scale and ensures reliability. The net effect is that your coding agent operates more like a well-managed development team than a single person: focused specialists doing what they do best, handing off to the next stage when ready, with automated gates preventing half-baked work from advancing.
Next: Integration Patterns
- Enable Codex Cloud for your repository
- Navigate to Codex Settings → Code Review
- Enable "Code review" for your target repositories
Usage Pattern:
# Agent Workflow with Automated Review
# 1. Agent implements feature
agent.execute_task(task_description)
agent.run_validation() # lint, typecheck, tests
pr = agent.create_pr()
# 2. Trigger Codex review
gh_api.add_comment(pr.number, "@codex review")
# 3. Wait for Codex review completion
review = wait_for_codex_review(pr.number, timeout=300)
# 4. Parse review comments
issues = parse_review_comments(review)
if issues.blocking_issues:
# 5. Agent addresses critical issues
for issue in issues.blocking_issues:
agent.fix_issue(
file=issue.file,
line=issue.line,
description=issue.comment,
suggestion=issue.suggested_change
)
# 6. Re-validate and push fixes
agent.run_validation()
git.push()
# 7. Request re-review
gh_api.add_comment(pr.number,
"Addressed Codex feedback. @codex review")
return pr
# Example output:
# PR #342: feat(auth): add JWT middleware
# - Agent implementation: 15 files changed
# - Codex review: 3 blocking issues, 5 suggestions
# - Agent fixes: 3 blocking issues resolved
# - Codex re-review: ✓ All blocking issues resolvedSpeculative fix loop: For fully autonomous flows, the agent can read Codex comments via GitHub APIs, apply fixes, re-run validations, and iterate until no blocking issues remain before requesting human review.
- Agent implements the feature and runs validations.
- Trigger Codex review by commenting on the PR.
- Parse review feedback and address blocking issues.
- Re-run validations, push fixes, and request re-review.